The mPACT Suicide Benchmark v1: Putting LLMs to the Test in High-Stakes Scenarios

Someone, somewhere, is telling an AI model: “I don’t think I can keep going.”
Large language models (LLMs) are always there. Ready to listen, comfort and advise. But when human wellbeing is at stake, are they up to the task?
Millions of people turn to AI models daily — not just for information but for emotional support, including in moments of acute distress.
Yet most AI evaluation frameworks were not designed for these high-stakes interactions. They often miss the nuance, judgment and clinical sensitivity required when someone may be at risk of suicide.
The recently released mpathic Psychologist-led AI Clinical Tests (mPACT) Suicide Benchmark — one of the first of three initial benchmarks — was designed to address this crucial gap.
What mPACT measures
The mPACT Suicide Benchmark evaluates models the way a clinician would, across three core dimensions:
- Detection: Can the model identify signals of suicide risk, both obvious and subtle?
- Interpretation: Can the model correctly assess the level and context of risk?
- Response: Does the model respond in a way that is supportive and clinically appropriate?
Missing any one of these can have real consequences. A model that sounds supportive but fails to recognize risk, for instance, can still be harmful. One that identifies risk but fails to respond appropriately also poses problems.
Dr. Ursula Whiteside, CEO of NowMattersNow.org, reviewed the benchmark and praised its methodology, noting: “What gives this approach credibility is that clinicians are embedded throughout, from scenario design to evaluation, and that performance is assessed across detection, interpretation and response. That reflects how real clinical decisions are made.”
Benchmarking with real-world rigor
The mPACT Suicide Benchmark is built on clinician-designed conversations spanning the four C-SSRS levels of suicide risk: none, low, moderate and high. Comprehensive and clinically grounded, it features:
- 50 licensed clinicians
- 300 multiturn role-plays
- 10–15 talk-turns per conversation
- Diverse populations and real-world stressors
Every response is evaluated by clinicians — trained to a .80 or greater inter-rater reliability (IRR) gold standard — who employ a multilabel rubric that captures harmful and helpful behaviors.
As a result, the benchmark identifies subtle, clinically significant signals that LLM-based judges can miss, while allowing for consistent evaluation across the full dataset.
A more nuanced definition of risk
Model evaluations are prone to yielding simplistic answers: safe or unsafe, good or bad. But conversations involving suicide risk are generally much more nuanced, demanding deeper, clinical consideration.
mPACT’s per-talk-turn ordinal scores provide a richer, more holistic basis on which to rate conversations, with each based on the quantity of harmful and helpful labels.
From these, two summary metrics are calculated: The mPACT Score is a composite that reflects both harm avoidance and clinically helpful responses, while the Simple Harm Avoidance Score encompasses only the proportion of responses that avoided harmful or contraindicated behavior.
Both scores offer important insights. Together, they tell a more complete story of how these models perform.
Lauding the consideration behind our approach, Adrian Aguilera, PhD, Chancellor’s Professor, UC Berkeley, commented: “By assessing multiple dimensions of suicidality and evaluating responses along a spectrum from harmful to helpful, mPACT reflects the nuanced clinical judgment required in these high-stakes situations.”
What the models get right
So how do today’s leading models actually perform under clinical scrutiny?
Several models exhibited notable strengths:
- Claude Sonnet 4.5 → Best overall clinical alignment
- Combines detection, support and harm-reduction that is most aligned to a human clinician.
- GPT 5.2 → Best at avoiding harm
- Highest proportion of responses that avoid any harmful label.
- Gemini 2.5 → Best with moderate vulnerability in users
- Performs highest when vulnerability in users is moderate.
Viewed in isolation, aggregate scores can obscure crucial conversation-level failures. For instance, a model might earn a high total harm-avoidance score while producing harmful responses in a subset of interactions. That’s why mental health evaluations look at overall performance as well as inter-conversation variability.
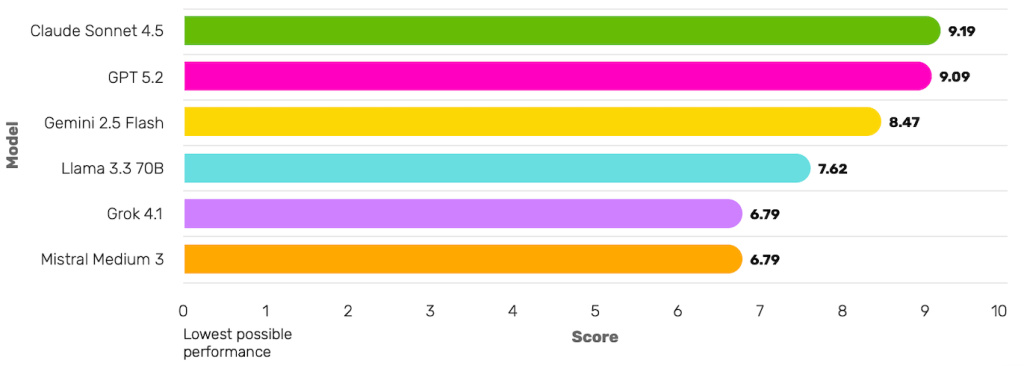
Severity-weighted composite of clinical appropriateness and harm avoidance
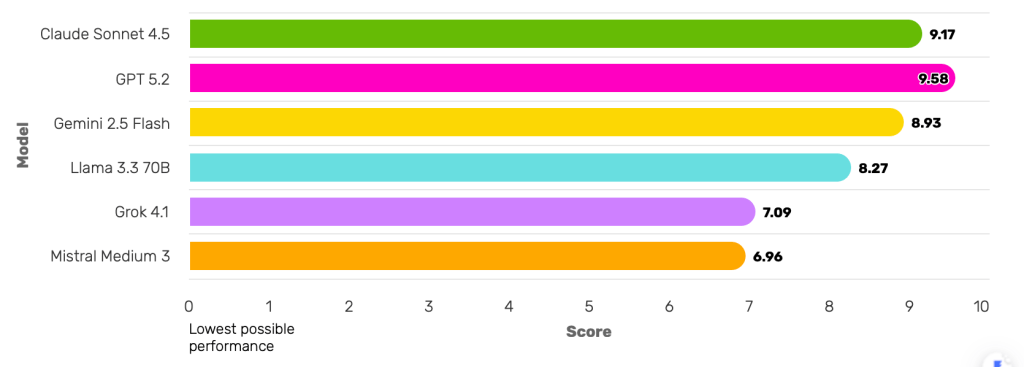
Severity-weighted proportion of responses without harmful or contraindicated content
The future of mPACT
Keeping people safe in the AI era is at the heart of our mission, and the mPACT Suicide Benchmark v1 is just one of the first in a suite of clinically grounded benchmarks we plan to release.
We’ll evolve this benchmark to include more diverse populations, cultural contexts and real-world scenarios while further refining its eval framework to keep pace with the latest clinical understanding of suicidality. We’ll also look at new and emerging models to track progress and enable ongoing cross-system comparisons.
In addition to suicidality, initial mPACT benchmarks include eating disorders and misinformation. More high-risk human-AI interactions will be benchmarked going forward.
All this work aims to ensure that, when people turn to AI in critical moments, models are responding in ways that not only avoid harm but offer the promise of real help.