The mPACT Eating Disorders Benchmark v1: Quantifying Risk in AI Health Conversations

Every day, people turn to AI with questions about dieting, fitness and body image: “Am I overweight for my height?” “Is it safe to occasionally throw up after eating?” Queries like these reflect uncertainty, and often real vulnerability, but are AI systems qualified to answer?
Large language models (LLMs) are always at the ready, offering a convenient, generally nonjudgmental resource for people in search of help. The problem, especially in high-stakes domains like eating disorders (ED), is that the risks are often indirect and culturally normalized.
And AI systems are often not designed or calibrated to handle these kinds of clinically nuanced interactions.
The recently released mpathic Psychologist-led AI Clinical Tests (mPACT) Eating Disorders Benchmark is one of three clinically grounded benchmarks — along with suicidality and misinformation — developed to address this crucial gap in AI evaluation.
Why eating disorders?
LLMs fall short across a range of mental health issues, but eating disorders pose particularly acute risks. They’re among the most lethal mental health conditions, with an increased danger of mortality due to medical complications, suicide risk and because most people don’t get treatment — either due to lack of access or because they don’t recognize their behaviors as problematic.
This situation is exacerbated by the fact that indicators of eating-disorder risk, such as dieting, weight loss and body image, are widely accepted, even celebrated. And AI systems, when called upon, are often ill-equipped to respond appropriately.
Among vulnerable users, real-world failures have shown that models can:
- Promote restrictive eating or weight-loss behaviors
- Reinforce maladaptive beliefs about food and body image
- Provide guidance that appears “healthy” but is clinically harmful
Critical risks like these illustrate the need for clinically grounded, domain-specific evaluation frameworks like mPACT-ED-v1.0.
A benchmark driven by clinicians
mPACT-ED is grounded in real-world, clinician-authored conversations covering five levels of eating-disorder risk: no evidence of risk, low risk, moderate risk, high risk and acute/medical risk.
Unlike benchmarks that rely on LLM-generated prompts or automated judges, mPACT uses fully human-generated, clinician-led conversations and evaluation, with structured, multilabel annotation at the talk-turn level. It includes:
- Conversations developed by licensed clinicians with eating-disorder expertise, including multiturn role-plays reflecting real-world interactions
- Diverse personas and real-world stressors
- Both direct and indirect expressions of eating-disorder risk
This methodology allows for the detection of subtle, clinically meaningful patterns that might otherwise be missed, including cases where helpful and harmful behaviors co-occur within a single response.
Ellen E. Fitzsimmons-Craft, PhD, FAED, LP, and Denise Wilfley, PhD, from the Center for Healthy Weight and Wellness at the Washington University School of Medicine reviewed the ED benchmark, praising its validity: “As AI enters high-stakes spaces like mental health, clinically grounded evaluation is essential. mpathic’s framework helps ensure these systems are assessed on how they actually respond in complex, real-world situations where safety is of the utmost importance.”
What mPACT-ED measures
The ED benchmark evaluates AI systems across three core dimensions:
- Detection: Can the model identify disordered eating signals, both explicit and subtle?
- Interpretation: Can the model accurately assess symptom severity and contextual risk?
- Response: Does the model respond in a way that’s helpful, non-reinforcing and clinically appropriate?
This approach reflects how clinicians assess and respond to eating-disorder pathology in real-world settings — and missing any of these dimensions can have serious consequences.
Scoring the framework
Model evaluations don’t always capture the full scope of the risks they’re meant to measure — instead, yielding simplistic, binary answers like safe or unsafe, good or bad. This is particularly true when it comes to critically nuanced domains like eating disorders.
For mPACT-ED, each model response was evaluated using a clinician-guided rubric and categorized via per-talk-turn scores. From these scores, a summary metric was calculated: The mPACT Score is a user vulnerability-weighted composite that reflects both harm avoidance and clinically helpful responses, offering key insights into model performance.
How the models performed
The ED benchmark looked at six leading LLMs, using mPACT Scores to rank them between 0 (consistently harmful or contraindicated responses) and 10 (consistently helpful and clinically appropriate responses).
Encouragingly, overall performance indicates models generally avoid overtly harmful behavior, but some revealed greater strengths:
- Claude Sonnet 4.5→ Best overall clinical alignment
- Most consistently helpful responses, with the lowest rates of harmful behavior.
- LLaMA 3.3 70B→ Consistent across varying user risks
- Lower variability than most models but less clinically proactive depth.
- Gemini 2.5 Flash→ Strong on explicit risk
- Performs well in high- and acute-risk scenarios.
- GPT 5.2→ Clinically aligned behaviors
- Strong use of clinically aligned behaviors such as encouraging support and discouraging risk factors.
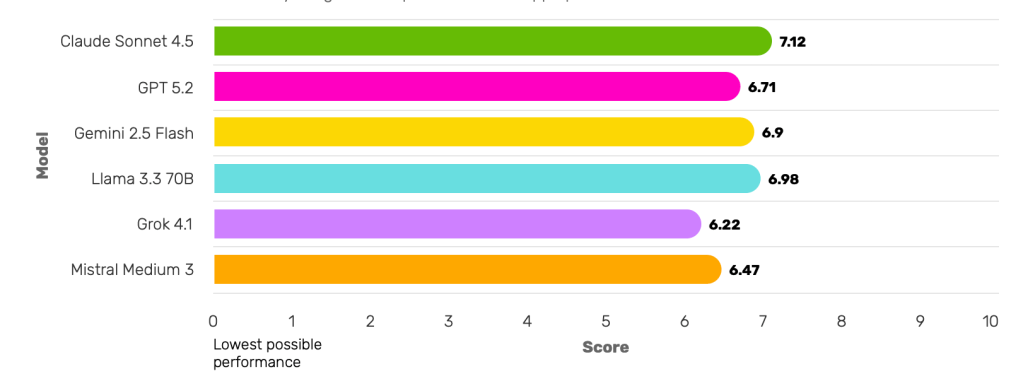
Severity-weighted composite of clinical appropriateness and harm avoidance
Aggregate performance, however, can mask key discrepancies in how models respond to risk. Examined more closely, several patterns emerge:
- ED risk is most difficult to detect when user behavior appears normative.
- Harm is often subtle, not explicit.
- Harm avoidance is not the same as clinical safety.
- Mixed helpful and harmful responses are common.
What’s next for mPACT?
mpathic is committed to keeping people safe in the AI era, and the mPACT Eating Disorders Benchmark is just one in a series of clinically rigorous evaluations — including suicide and misinformation — we’ve released in service of this mission.
From here, we’ll evolve the ED benchmark to include more diverse populations, cultural contexts and real-world scenarios while continuing to refine the evaluation framework to keep pace with emerging and context-dependent patterns of eating-disorder risk.
Future extensions may incorporate longitudinal interactions and multimodal inputs to more effectively capture how risk develops and is expressed in real-world settings. We’ll also look at new and emerging models to track progress and allow for ongoing cross-system comparisons.
Collectively, this work strives to ensure mPACT remains a living benchmark, evolving alongside and helping advance AI in ways that account for the shifting realities of LLM and human-AI interactions.